
Here’s a pretty interesting graphic from Pollster.com:
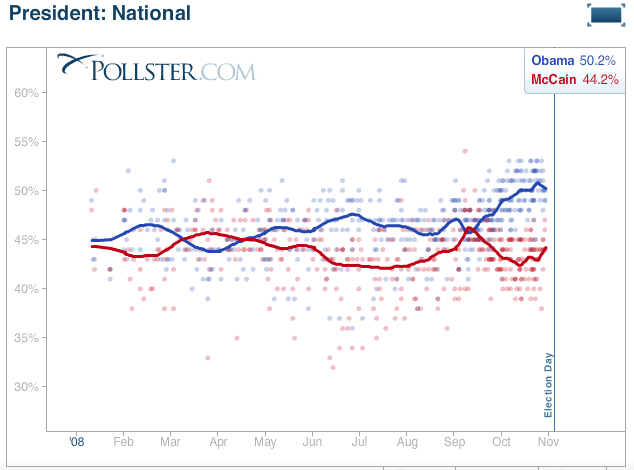
As you can see, the graph summarizes a large number of individual polls measuring support for the two major party candidates from January 1 to October 26. The site indicates that it includes all publicly available polls during the time period. Each poll result is represented with two markers — blue for Obama and red for McCain. The red and blue trend lines are “trend estimates” based on local regressions for the values of the corresponding measurements for a relatively short interval of time (the site doesn’t explicitly say what the time interval is). So, for example, the trend estimate for August 1 appears to be approximately 47%:42% for the two candidates. As the site explains, 47% is not the average of poll results for Obama on August 1; instead, it is a regression result based on the trend of all of Obama’s polling results for the previous several days.
There are a couple of things to observe about this graph and the underlying methodology. First, it’s a version of the “wisdom of the crowd” idea, in that it arrives at an estimate based on a large number of less-reliable individual observations (the dozen or so polling results for the previous several days). Each of the individual poll results has an estimate-of-error which may be in the range of 3-5 percentage points; the hope is that the aggregate result has a higher degree of precision (a narrower error bar).
Second, the methodology attempts to incorporate an estimate of the direction and rate of movement of public opinion, by incorporating trend information based on the prior several days’ polling results.
Third, it is evident that there is likely to be a range of degrees of credibility assigned to the various component polls; but the methodology doesn’t assign greater weight to “more credible” polls. Ordinary readers might be inclined to assign greater weight to a Gallup poll or a CBS poll than a Research2000 or a DailyKos poll; but the methodology treats all results equally. Likewise, the critical reader might assign more credibility to a live phone-based poll than an internet-based or automated phone poll; but this version of the graph includes all polls. (On the website it is possible to filter out internet-generated or automated phone polling results; this doesn’t seem to change the shape of the results noticeably.)
There is also a fundamental question of validity and reliability that the critical reader needs to ask: how valid and reliable are these estimates for a particular point in time? That is, how likely is it that the trend estimate of support for either candidate on a particular day is within a small range of error of the actual value? I assume there is some statistical method for estimating probable error for this methodology, though it doesn’t appear to be explained on the website. But fundamentally, the question is whether we have a rational basis for drawing any of the inferences that the graph suggests — for example, that Obama’s lead over McCain is narrowing in the final 14 days of the race.
Finally, there is the narrative that we can extract from the graph, and it tells an interesting story. From January through March candidate Obama has a lead over candidate McCain; but of course both candidates are deeply engaged in their own primary campaigns. At the beginning of April the candidates are roughly tied at 45%. From April through September Obama rises slowly and maintains support at about 48%, while McCain falls in support until he reaches a low point of 43% in the beginning of August. Then the conventions take place in August and early September — and McCain’s numbers bump up to the point where Obama and McCain cross in the first week of September. McCain takes a brief lead in the trend estimates. His ticket seems to derive more benefit from his “convention bump” than Obama does. But in the early part of September the national financial crisis leaps to center stage and the two candidates fare very differently. Obama’s support rises steeply and McCain’s support falls at about the same rate, opening up a 7 percentage point gap in the trend estimates by the middle of October. From the middle of October the race begins to tighten; McCain’s support picks up and Obama’s begins to dip slightly at the end of October. But the election looms — the trend estimates tell a story that’s hard to read in any way but “too late, too little” for the McCain campaign.
And, of course, it will be fascinating to see where things stand a week from today.
Here is the explanation that the website offers of its methodology:
[quoting from Pollster.com:]
“Where do the numbers come from?
When you hold the mouse pointer over a state, you see a display of the latest “trend estimate” numbers from our charts of all available public polls for that race. The numbers for each candidate correspond to the most recent trend estimate — that is the end point of the trend line that we draw for each candidate. If you click the state on the map, you will be taken to the page on Pollster.com that displays the chart and table of polls results for that race.
In most cases, the numbers are not an “average” but rather regression based trendlines. The specific methodology depends on the number of polls available.
- If we have at least 8 public polls, we fit a trend line to the dots represented by each poll using a “Loess” iterative locally weighted least squares regression.
- If we have between 4 and 7 polls, we fit a linear regression trend line (a straight line) to best fit the points.
- If we have 3 polls or fewer, we calculate a simple average of the available surveys.
How do regression trend lines differ from simple averages?
Charles Franklin, who created the statistical routines that plot our trend lines, provided the following explanation last year:
Our trend estimate is just that, an estimate of the trends and where the race stands as of the latest data available. It is NOT a simple average of recent polling but a “local regression” estimate of support as of the most recent poll. So if you are trying to [calculate] our trend estimates from just averaging the recent polls, you won’t succeed.
Here is a way to think about this: suppose the last 5 polls in a race are 25, 27, 29, 31 and 33. Which is a better estimate of where the race stands today? 29 (the mean) or 33 (the local trend)? Since support has risen by 2 points in each successive poll, our estimator will say the trend is currently 33%, not the 29% the polls averaged over the past 2 or 3 weeks during which the last 5 polls were taken. Of course real data are more noisy than my example, so we have to fit the trend in a more complicated way than the example, but the logic is the same. Our trend estimates are local regression predictions, not simple averaging. If the data have been flat for a while, the trend and the mean will be quite close to each other. But if the polls are moving consistently either up or down, the trend estimate will be a better estimate of opinion as of today while the simple average will be an estimate of where the race was some 3 polls ago (for a 5 poll average– longer ago as more polls are included in the average.) And that’s why we estimate the trends the way we do.”

A Bold SuggestionMany people suffer from guessing. Experts of statistics might suffer from or enjoy guessing.As banking could be moved to Internet safely, Internet has been able to provide poll for citizens safely and with extreme low cost. Then we do not need to collect sample data, do lots of statistical analysis, and have inconclusive conclusion for a year or longer.From either sociology or management perspective, poll is an evaluation of those president candidates by citizens. With ordinary information technology, we could do this kind of evaluation more frequently, probably quarterly or twice a year. The result of each poll does not have to have power to decide whether the President of US could keep his position or not. But the result of those polls reflects real worries or confidence of citizens about their government, and we will not suffer so much from inconclusive statistical analysis.
LikeLike