
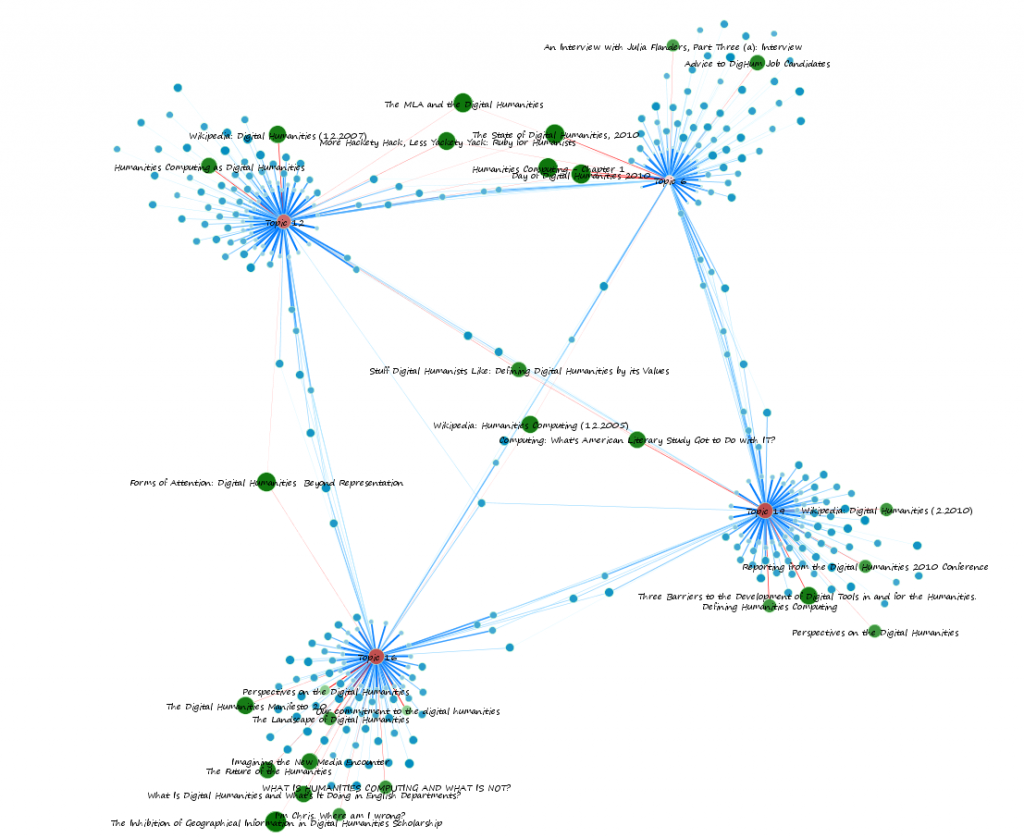
One of the innovative papers I heard at the SSHA last week was a presentation by Harvard graduate student Ian Miller, with a paper called “Reading 500 Years of Chinese History at Once”. (In the end Ian apologized for only getting to the last 188 years of the Qing Dynasty.) I won’t mention the details, since Ian hasn’t yet published any of this work. But it was a genuinely fascinating exploration of emerging tools in the “digital humanities,” to apply topic analysis to a 188-year series of Imperial memoranda. Ian’s goal was to identify spikes of interest in topics such as rebels and bandits, and the work was really fascinating to hear about. (Here are a couple of interesting pages on digital humanities; link, link.)
The basic insight that is leading to new research in digital humanities is the fact that vast quantities of texts are now available for quantitative analysis. Humanists typically work with texts, and up till now their approaches have largely taken the form of close readings and semantic interpretations. Now that much of the published corpus of humanity is available in digital form thanks to the Google Books project, and now that many archives are steadily moving their ephemera to digital versions as well, it is possible for humanities researchers to broaden their toolkit and look for patterns among these published and unpublished texts. Google’s NGrams tool allows all of us to do some of this kind of work (link, link), but more specialized tools for statistical analysis and presentation are needed if we are to go beyond compiling of changing frequencies of specific terms.
Statistical techniques for discovering “topics” in documents represent a crucial step forward in this endeavor. As Nelson Goodman noted in a pre-digital time, knowing what a text is “about” requires more than simply knowing what words are included in the document in what frequencies (Problems and Projects). We might have said at that point in the 1960s, that what we need beyond the syntax and the list of terms, is “understanding”, an irreplaceably human capability. But a central task for web-based search arises from exactly this issue, and a great deal of research has been done to attempt to do a better job of discovering the “topics” that are central in a given document without invoking a human reader. And surprisingly enough, real progress has been made. This progress is at the heart of the digital humanities. The fundamental problem is this: are there statistical methods that can be used to analyze the frequency of the words included in a given document to provide a compressed analysis of the “topics” included in the document? We might then say that this compressed representation is a good approximation to what the document is “about”.
A theoretical advancement, and corresponding set of tools, that is frequently invoked in research projects in this field is a “latent Direchet allocation” (LDA), a statistical technique for using word frequencies in a document to sort out a smaller set of topics. David Blei, Andrew Ng, and Michael Jordan introduced the idea in 2003 (link). (There is a detailed and technical description of the model in Wikipedia; link.) They indicate that this method is similar to algorithms based on “latent semantic indexing”. Here is how Blei, Ng, and Jordan describe the approach in the abstract to this paper:
We describe latent Dirichlet allocation (LDA), a generative probabilistic model for collections of discrete data such as text corpora. LDA is a three-level hierarchical Bayesian model, in which each item of a collection is modeled as a finite mixture over an underlying set of topics. Each topic is, in turn, modeled as an infinite mixture over an underlying set of topic probabilities. In the context of text modeling, the topic probabilities provide an explicit representation of a document. We present efficient approximate inference techniques based on variational methods and an EM algorithm for empirical Bayes parameter estimation. We report results in document modeling, text classification, and collaborative filtering, comparing to a mixture of unigrams model and the probabilistic LSI model.
And here is their statement of the goal of LDA analysis:
The goal is to find short descriptions of the members of a collection that enable efficient processing of large collections while preserving the essential statistical relationships that are useful for basic tasks such as classification, novelty detection, summarization, and similarity and relevance judgments. (993)
And here is a summary assessment of the effectiveness of the LDA representation of a set of documents relative to a less compressive representation:
We see that there is little reduction in classification performance in using the LDA-based features; indeed, in almost all cases the performance is improved with the LDA features. Although these results need further substantiation, they suggest that the topic-based representation provided by LDA may be useful as a fast filtering algorithm for feature selection in text classification. (1013)
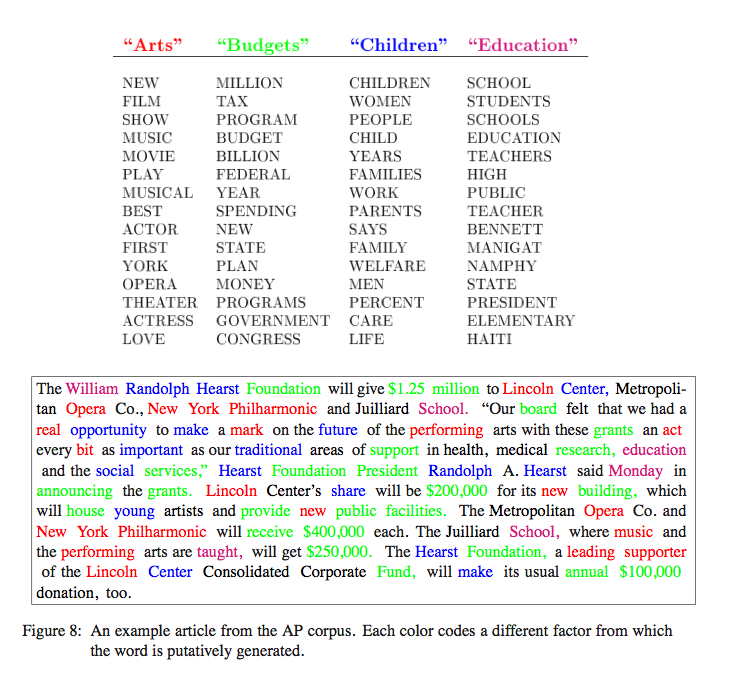
Here is a table they provide illustrating the kind of topic analysis that this statistical methodology creates:
In some ways the type of application that Ian Miller is making of these tools seems ideal. This kind of statistical methodology can be applied to very large databases of historical texts in order to discover patterns that the authors of those texts would have been entirely unaware of. So methods like LPA seem well designed to uncover historically shifting patterns of topic emphasis by observers and policy makers over time and space.
This is just a first cut for me on the kind of reasoning and statistical analysis that information theorists are employing to do semantic analysis of documents, and I certainly don’t have a good understanding of how this works in detail. The power of these frameworks seems very great, though, and well worth studying in greater detail by historians and humanists.
