

Here is a fascinating and ambitious “big data” project that aims at probing and mapping the structure of the disaggregated university curriculum in the United States and other English-speaking countries. The project is called the Open Syllabus Project and is hosted at Columbia University with a team including Joe Kraganis (project director), David McClure (Stanford University Library), Dnnis Tenen, Jonathan Stray, Alex Gil, and Ted Byfield, along with others. The project has collected over a million syllabi that are openly accessible on university websites; it has then created a database of the books and articles included in these syllabi. There are currently 934K items in the database of texts.
The project provides two basic tools. First, it allows users to search the database by title and see its frequency and co-references. It is also possible to filter by field, institution, state, and country; for each title it is possible to find the other titles most commonly associated with it in the filtered field of syllabi.
One immediate interest in this project is to see the top 10 or twenty titles overall and in various fields. Overall The Elements of Style, the Republic, the Communist Manifesto, Biology, and Frankenstein are the top five titles. In sociology the top five include Aristotle’s Ethics, JS Mill’s Utilitarianism, Plato’s Republic, Descartes’ Meditations, and Aristotle’s Nicomachean Ethics. In politics the top five include Huntington’s Clash of Civilizations, Hobbes’ Leviathan, Tocqueville’s Democracy in America, Aristotle’s Politics, and Machiavelli’s Prince.
These listings give a somewhat musty feel to the collective curriculum — the most common titles are “classics” at least 150 years old. (Sam Huntington’s Civilizations book and Ken Waltz’s Theory of International Politics are the only 20th century works of political science in the politics field top ten. Ranks 11-20 are more contemporary.) This might give the impression that the typical syllabus is dominated by the classics — not very encouraging for anyone who thinks that new ideas are needed to solve contemporary problems. But that impression is probably a statistical illusion. If the canon is relatively small (perhaps 100 titles) and the more contemporary and topical literature is very large (10,000 titles) then it is likely enough that items in the canon will show up more frequently, if only because there are lots of introductory courses in which those titles are used. There will be a broad spread of the more contemporary titles over the large number of syllabi, with the result that only a few will break through into the top rank.
Here is an example — my own Varieties of Social Explanation.

VSE appears in 62 syllabi in the database, and it is most commonly paired with Kuhn, Elster, Taylor, Lijphart, Fearon, and Winch. The syllabi including VSE break down by discipline like this: sociology (23), politics (5), economics (5), psychology (4), philosophy (1), other (28). There are 200 titles with which it is paired in at least four syllabi. Some of these would fit handily into a philosophy of social science course; others are more distant.
The most interesting tool currently available through the project is an interactive network graph of the 10,000 most frequently cited titles.
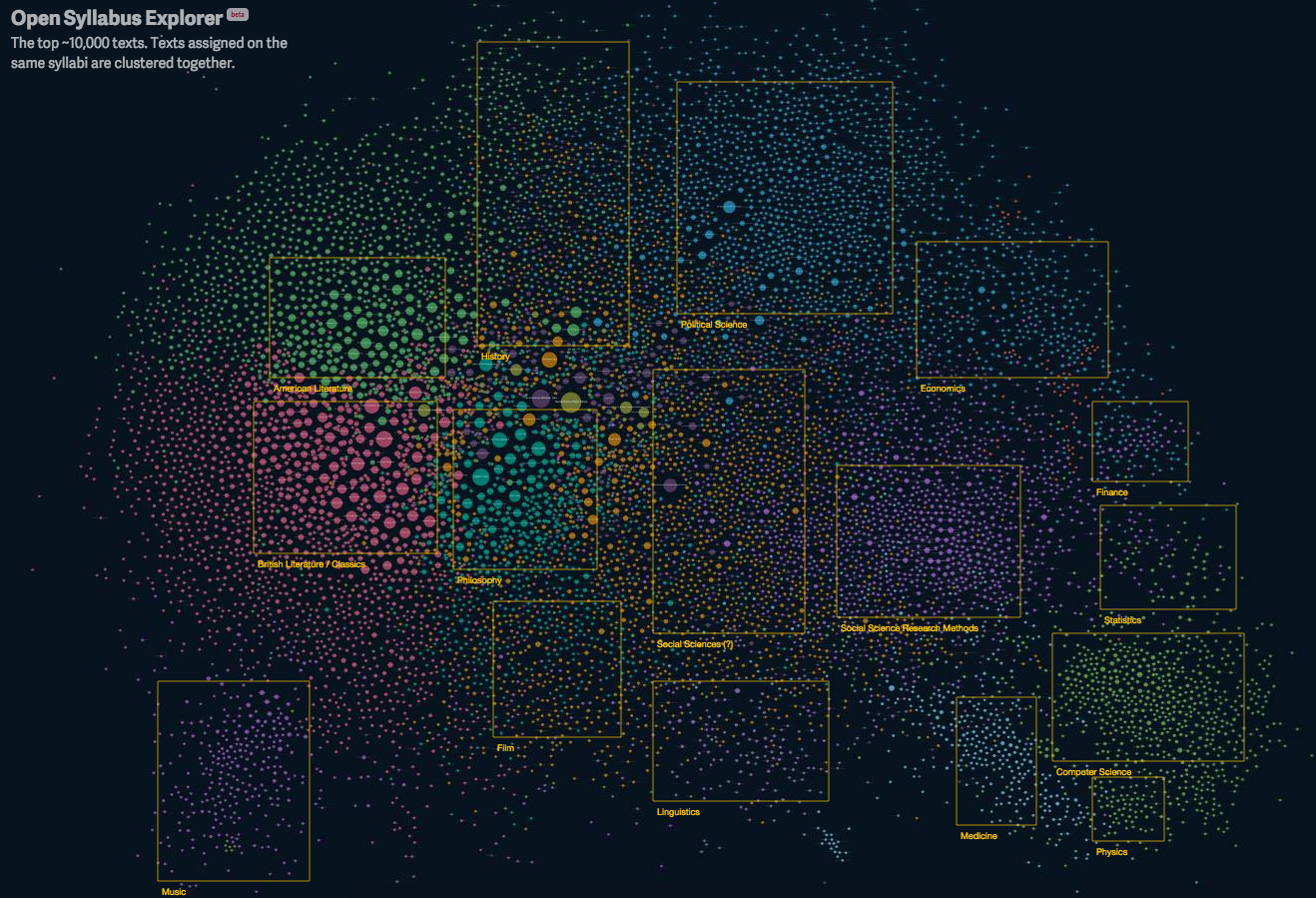
The methodology is not fully explained on the website, but it appears that items are assigned a metric to other titles based on the frequency of cross-reference between them. It results in an intriguing map of knowledge across the galaxy of disciplines. It is possible to zoom in on any region; below is a snapshot within the social science cluster.
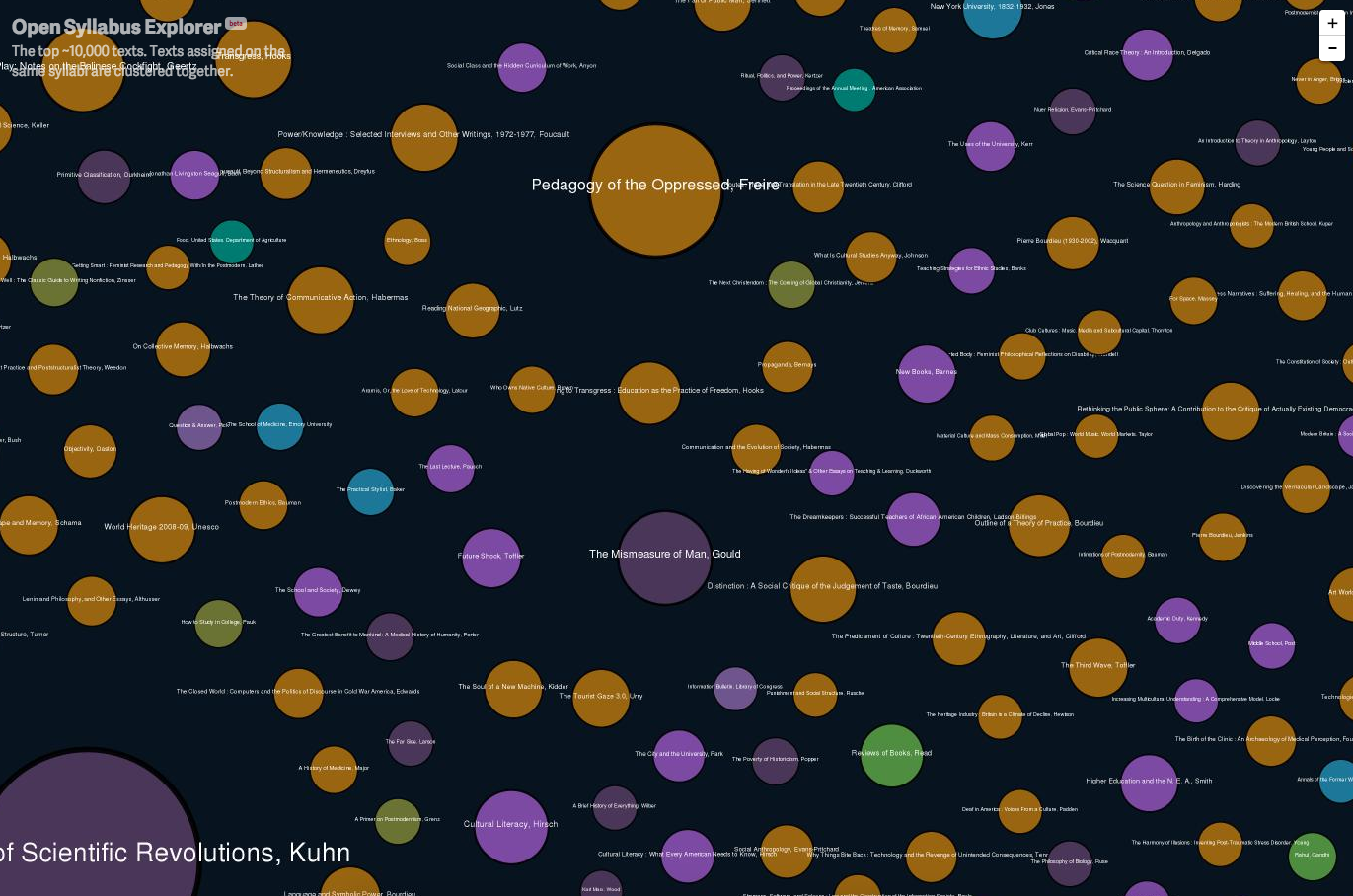
It is possible to pick out the classics in the field — Durkheim, Weber, Mead, Dewey, Goffman, Bourdieu, Freire — in this cluster of titles. But this should not be equated with importance or influence. One’s eye may be drawn to the large central references in this graph — Thomas Kuhn’s The Structure of Scientific Revolutions, for example, and these may appear as stars around which other items revolve. But equally interesting are the titles on the periphery and in the interstices — titles which occur with a measurable frequency within the corpus of syllabi but which have relatively fewer affinities with other titles. And in fact many specialists in the various fields would probably find the most innovative works in their discipline on the periphery rather than in the core of these clusters.
This project is a great example of a big-data problem in the sociology of knowledge. The very hard question now is what to make of it; what light does it shed on the structure of university instruction and knowledge conveyance? What analytical questions need to be posed to this data set?
