

One element of the NSA revelations of the past month is the apparent fact that the NSA’s PRISM program enables the agency to collect wholesale the transactions that occur on the Internet, including email header information. This follows the revelation that all metadata for phone calls made on the Verizon network (and presumably others) have been collected for a period of time — perhaps as long as seven years. A story by John Naughton in the Guardian (7 July 2013) highlights the intrusiveness that wholesale exposure of communications metadata creates for each individual’s privacy — without ever looking into the contents of the communications.
An MIT research group has created a tool called Immersion to allow anyone to graph his or her own email communications network (link). This is a very powerful tool, and it is accessible to all of us. So it is an experiment well worth undertaking.
Here are the results for my own case. In the past three years I’ve transacted something like 60,000 email exchanges. The Immersion tool is able to analyze the metadata of this set of exchanges in a few minutes, and the resulting graphs are stunning. The vast and apparently disorderly library of messages turns out to have a very simple and revealing order. (I’ve removed the individual names from the graph, but these names are provided by the Immersion tool. An “analyst” would be able to focus in on any point of interest by name.) Here is the graph for the past three years of my communications:
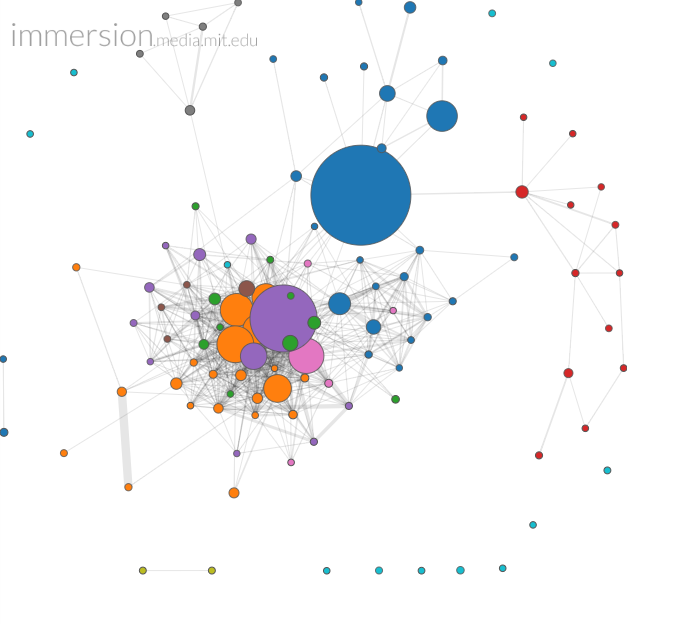
It is important to understand the inputs to this analysis. Only the data from my own email library has been used. Lots of connections are represented in the graph between other people. But these connections all come from my own email cache — as cc’s on messages to or from me. Second, I am not represented on the graph. Rather, each circle is one of the 250 or so people with whom I have had email contact in the past three years. Each circle’s diameter represents the volume of flow between that person and me; and the breadth of the links between individuals represents the volume of flow between them as registered in my email cache. (The program apparently has a smart way of excluding messages from organizations like newsletters.)
It is evident that the graph simplifies my social network substantially (as captured by my email traffic). In fact, it is possible to dissect the graph into several key core groups: the local administrators at the campus where I work, the administrators at the system level of the university, a group of family members, a small group of researchers with whom I communicate and who communicate with each other, a journal editorial group, and a non-profit organization I’m involved in. (There are also students on the graph, but they are single dots, since my email does not provide evidence of email connections among them. Likewise, there are other single-point researchers with whom I communicate (the blue dots lower right), but my cache doesn’t indicate communications among them.) So here is the same graph with labels for the distinct groups:
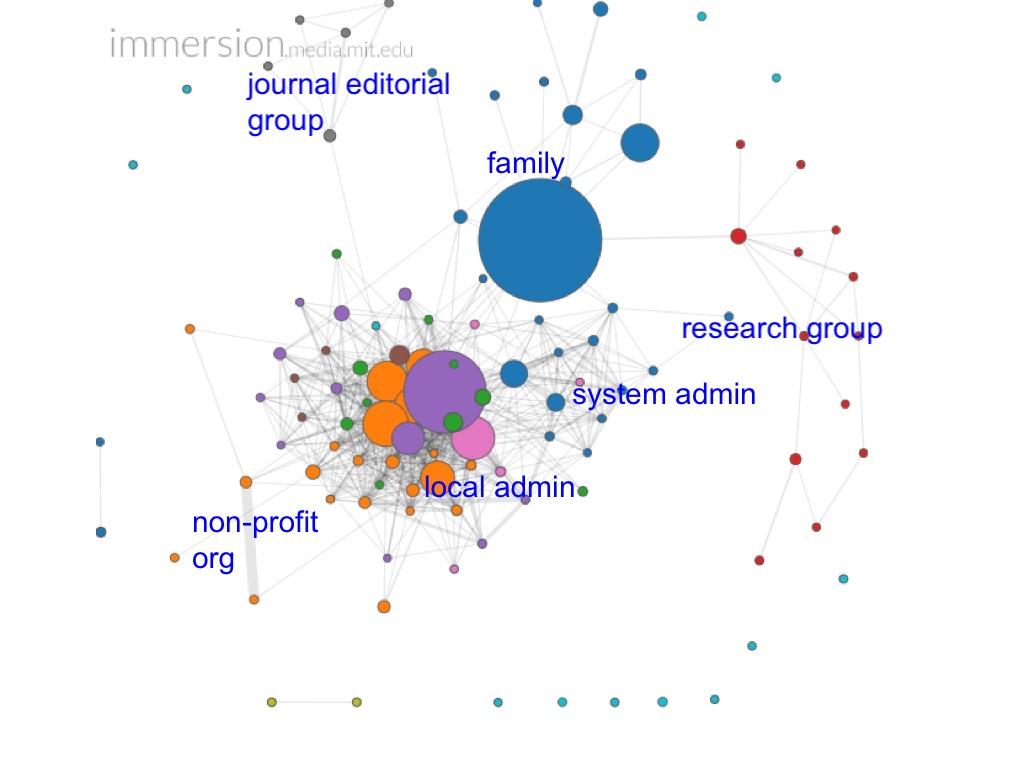
It is interesting to observe that there are lots of inter-group communications between members of the two administrative groups, but the two groups are clearly distinguished nonetheless on the graph. The intra-group communication for each is dense enough to pull the two systems apart. This algorithmic network analysis, based on a very limited set of data, accurately uncovers the organizational structure and hierarchy of the university and the campus administrative groups. Also of interest is the fact that the graph does a decent job of analyzing other people’s relationships — without any data from them!
In other words — 60,000 messages boil down to a pretty simple and accurate picture of one person’s activities over the past three years.
Another facility that the Immersion tool provides is the ability to graph the recorded connections from any single person to everyone with whom he/she has communicated (out of my list of persons). The large purple circle in the first graph is the chief academic officer on my campus, who reports to me. This is the person with whom I communicate most frequently within the university. (By looking at the month-to-month frequency of communication, also provided by Immersion, it is also possible to single out the months where crises arose.) It is possible to blow up the circle of this individual’s network as well, and see which individuals are most frequent connections (again, as recorded by cc’s and forwards of messages from other people included in my own in-box). Here is the graph of the CAO’s network:
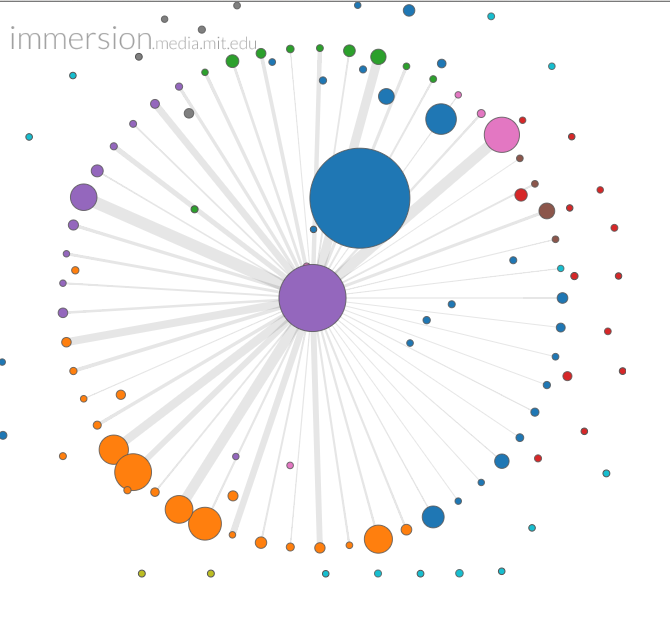
Now think how much more informative these graphs would be if an agency also had access to the email caches of the two hundred or so people represented here. Communications between X and Y that are minor or non-existent on my graph, may turn out to have broad links when this larger set of data is incorporated. And this is exactly the capability that most observers are now attributing to the PRISM and telephone capture programs of the NSA.
What this implies to me is that the people who are most worried about the NSA’s wholesale data collection programs are probably right. The data that is being collected — phone and email metadata, perhaps auto license readers, credit card transactions, and electronic toll and transportation cards as well — this fund of data suffices to map out our personal lives in much, much greater detail than we would ever have imagined possible in a democratic society. We no longer have the luxury of “privacy through anonymity” or “haystack privacy”. Once there is full information recorded over time of our electronic transactions (including, remember, locational data from our phones), our lives can be played back in detail at any point. And the Immersion tool shows that the software exists to make sense of such vast databases, enabling agencies to produce customized and individually tailored “dossiers” for all of us.
The revelations about the FISA court in today’s New York Times certainly support skepticism about the notion that these capabilities are carefully and properly controlled by the FISA process (link). Here is a particularly worrisome finding in the NYT article:
The officials said one central concept connects a number of the court’s opinions. The judges have concluded that the mere collection of enormous volumes of “metadata” — facts like the time of phone calls and the numbers dialed, but not the content of conversations — does not violate the Fourth Amendment, as long as the government establishes a valid reason under national security regulations before taking the next step of actually examining the contents of an American’s communications.
This legal theory specifically permits the kind of wholesale collection of metadata that can be used in the ways described here. And that is surely a profound threat to our privacy.
